RescueOMR: batch Optical Mark Recognition without foresight
RescueOMR is a set of tools to perform batch OMR (Optical Mark Recognition, ie: detect check-marks on paper questionnaires) on a loose set of scanned documents.
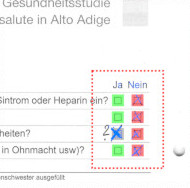
RescueOMR uses image-matching to identify and locate the checkmarks to be analyzed, without any document preparation. This allows for printing defects, page and even document variations to be accounted for without foresight.
The checkmark structure can be reconstructed directly from the final print using just a sample page, Gimp and Inkscape.
Read the usage tutorial for an hands-on demonstration.
Download
This project doesn’t have a fixed release schedule yet. All the relevant source/developer information can be found on Github.
You can download the latest sources directly with:
https://github.com/EuracBiomedicalResearch/RescueOMR/archive/master.zip
Overview
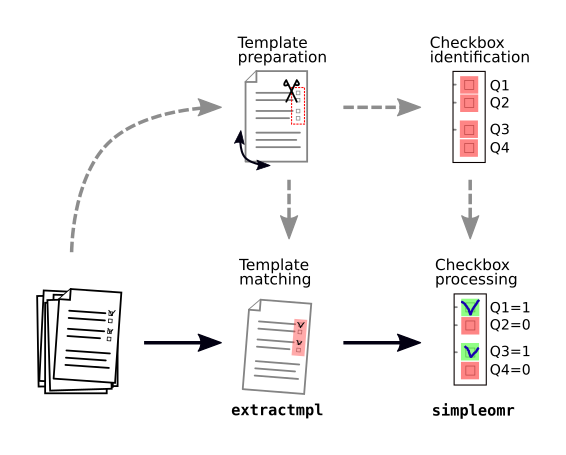
RescueOMR consists of two main tools used together in sequence:
| extractmpl: | locate a template within a larger image and return a registered image that can be used for OMR |
|---|---|
| simpleomr: | given a registered image and checkbox locations, returns the status (ticked/unticked) of each in tabular format |
In the simplest usage scenario, the following illustrates how a new questionnaire is prepared and then processed:
Template preparation
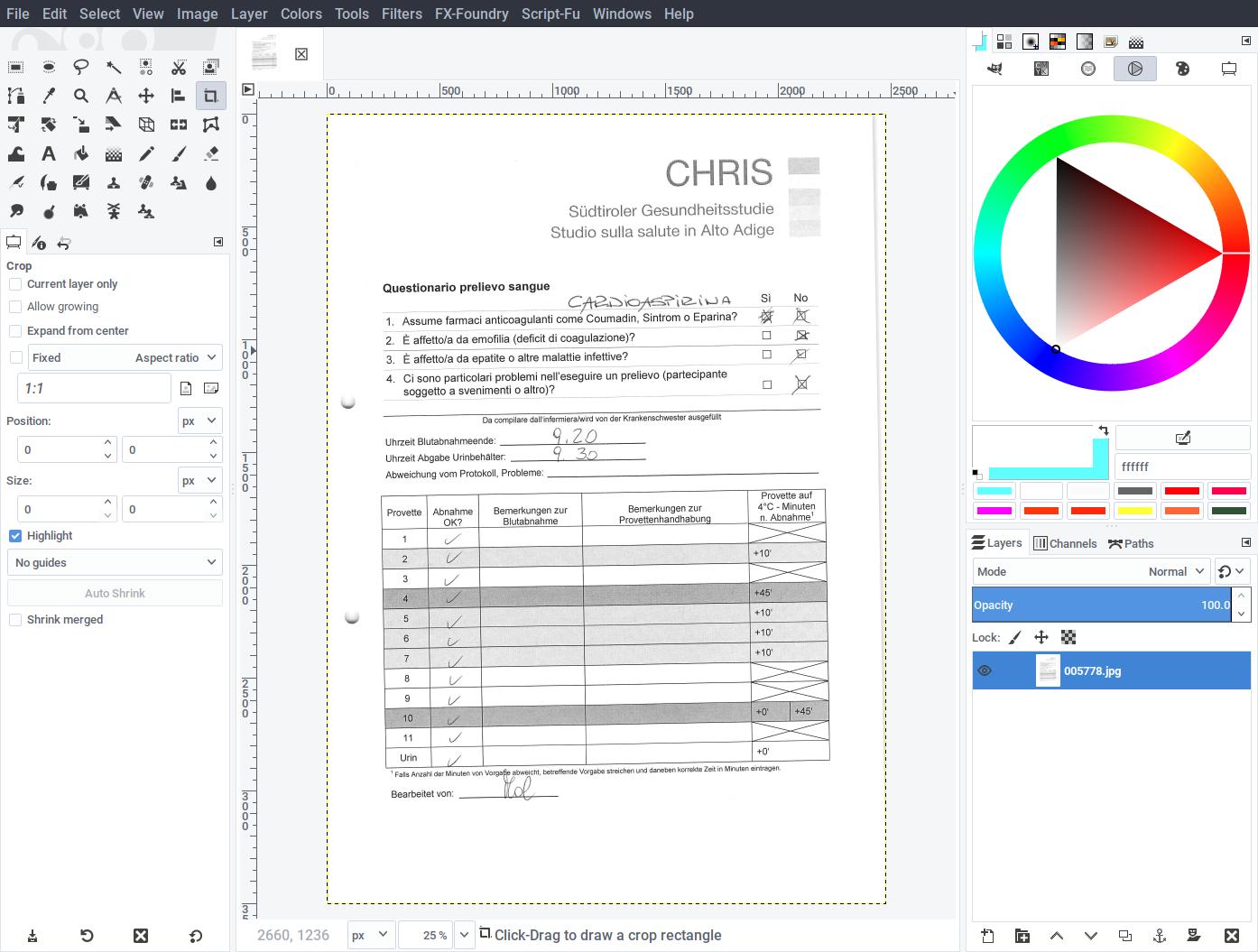
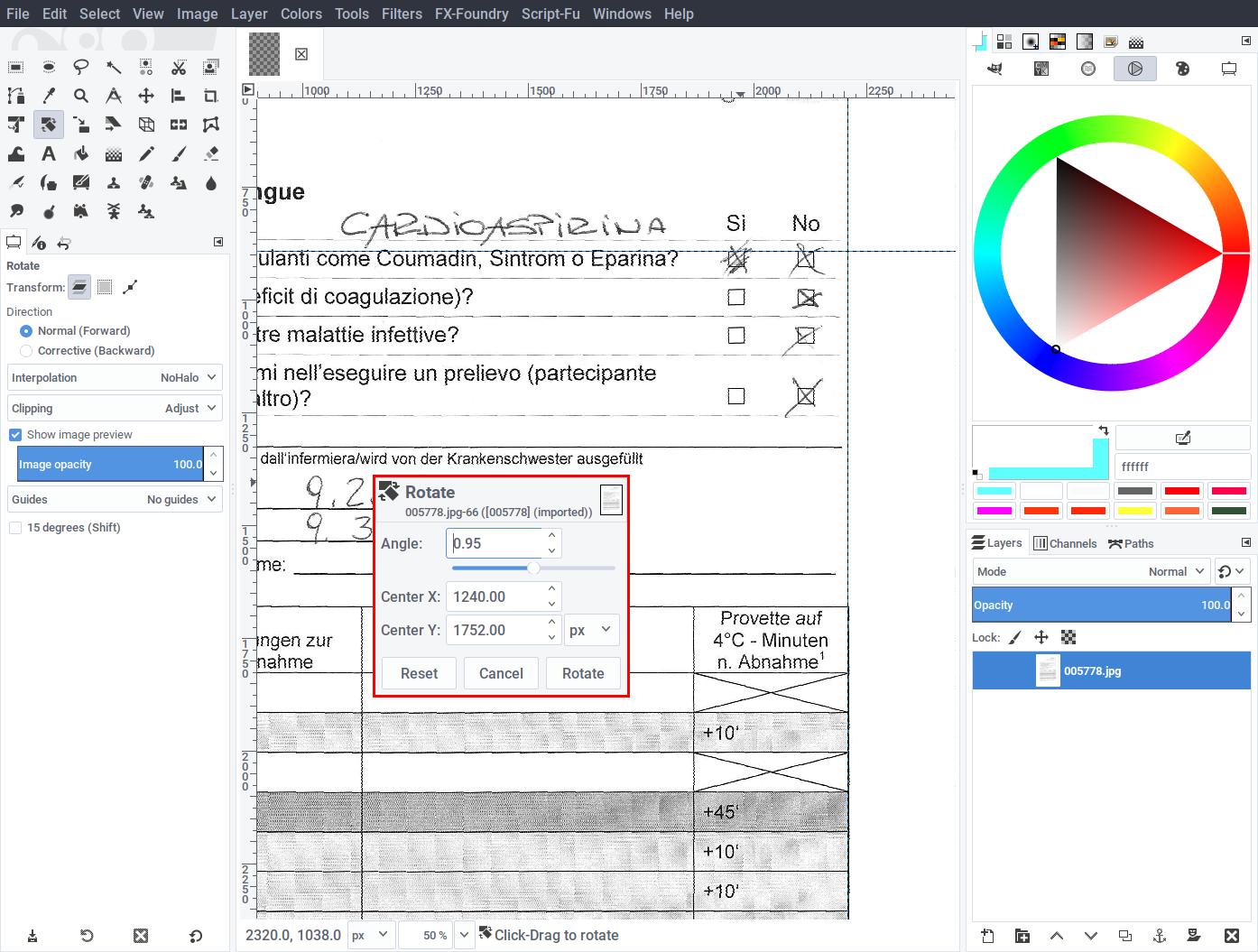
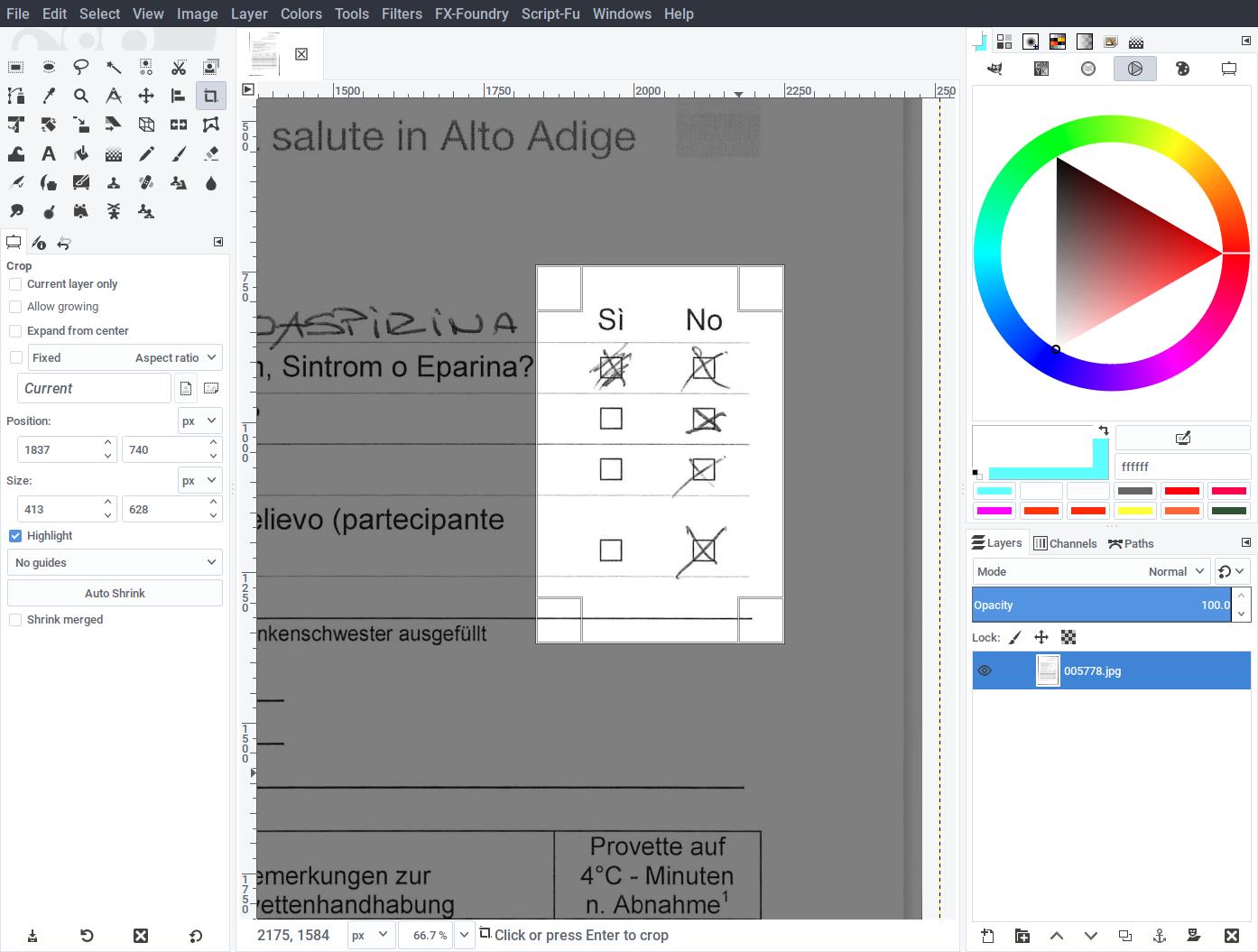
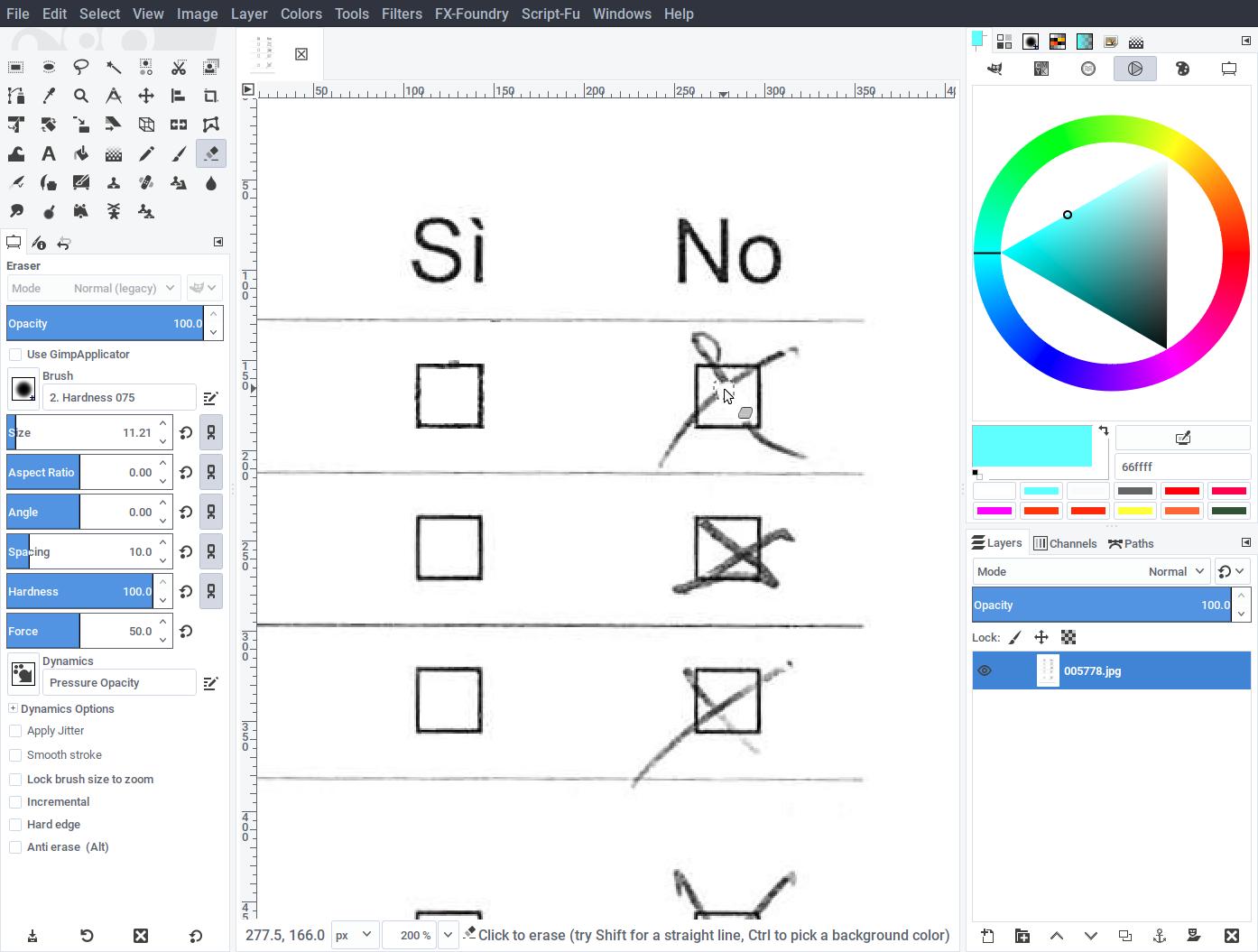
- Scan a page of the questionnaire containing the checkboxes at 300dpi in grayscale. Open the image with an editor such as Gimp.
- With the aid of guides, correct the image (rotate and deskew as needed) so that checkboxes become square and straight.
- Crop the area around the checkboxes, leaving some surrounding detail.
- Cleanup any pen marks, so that checkboxes become empty.
- Save the resulting image as template.png
Identifying checkbox locations
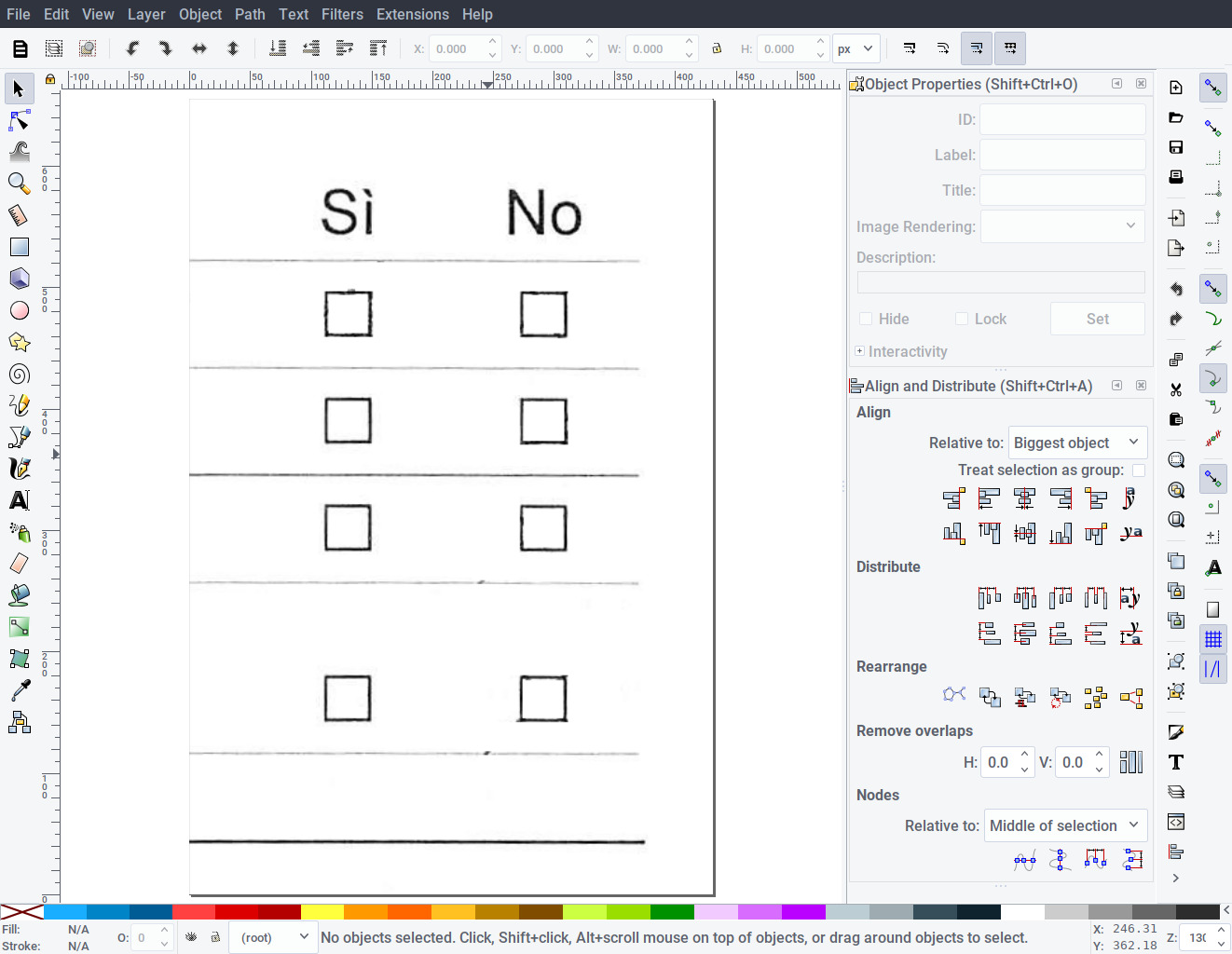
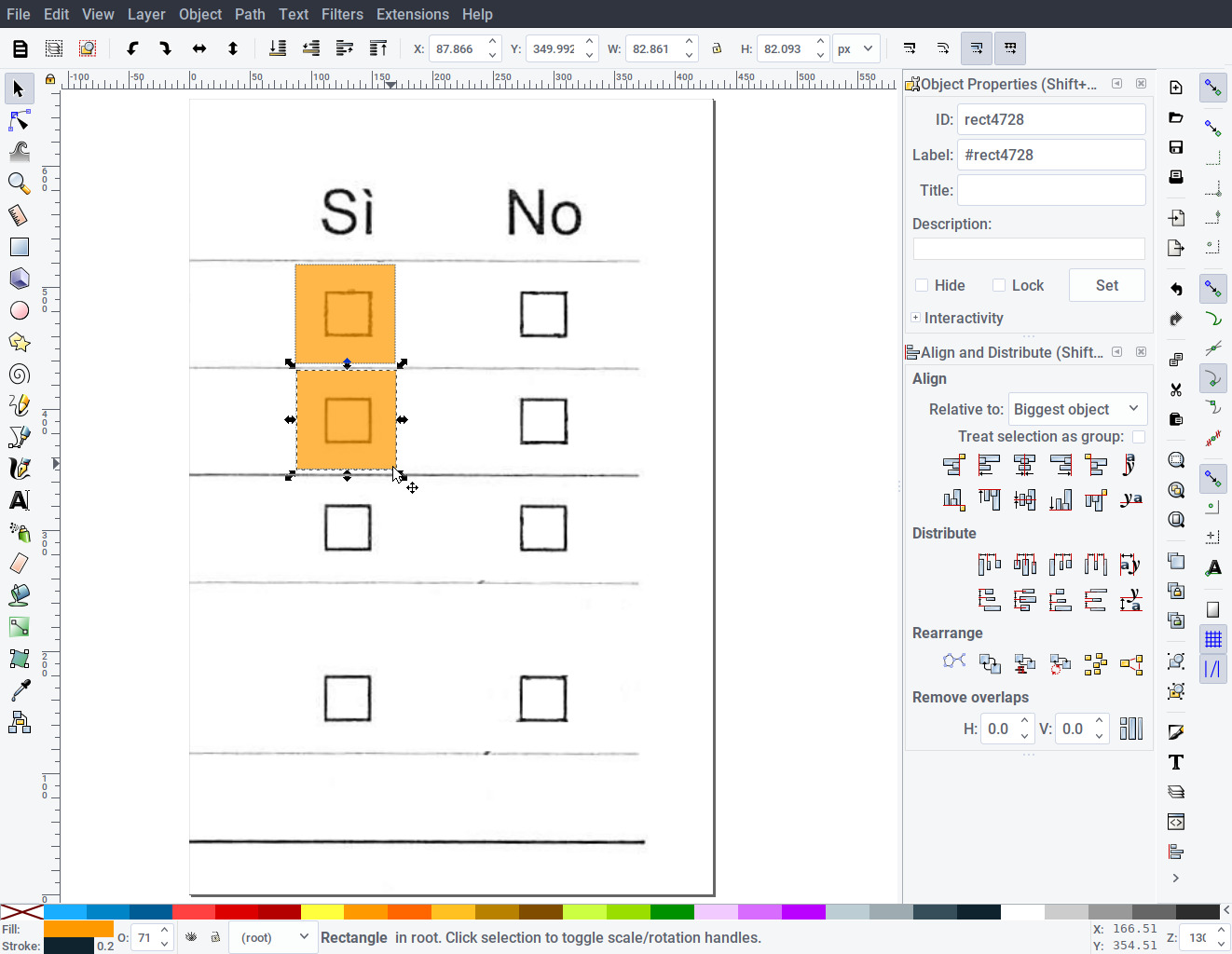
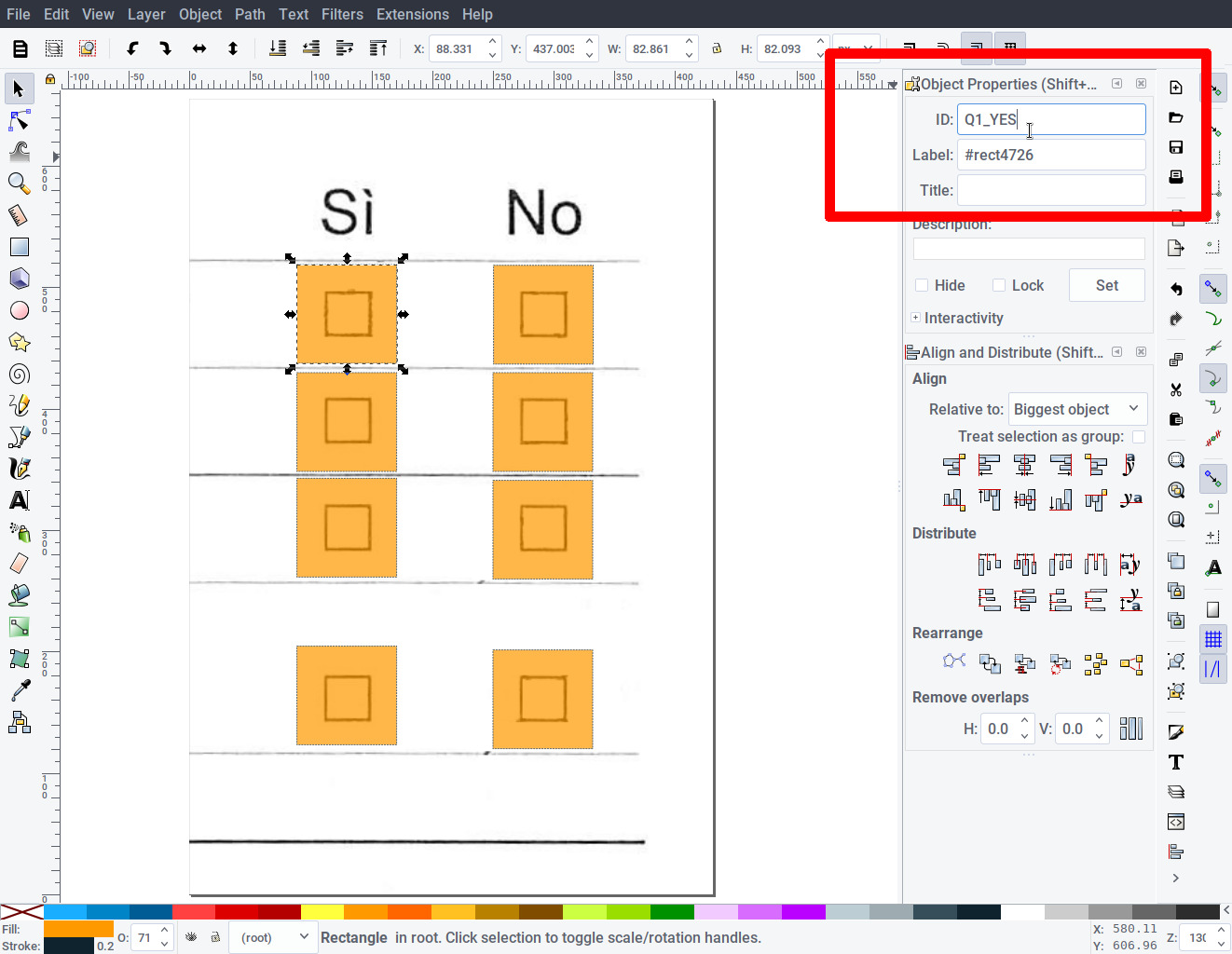
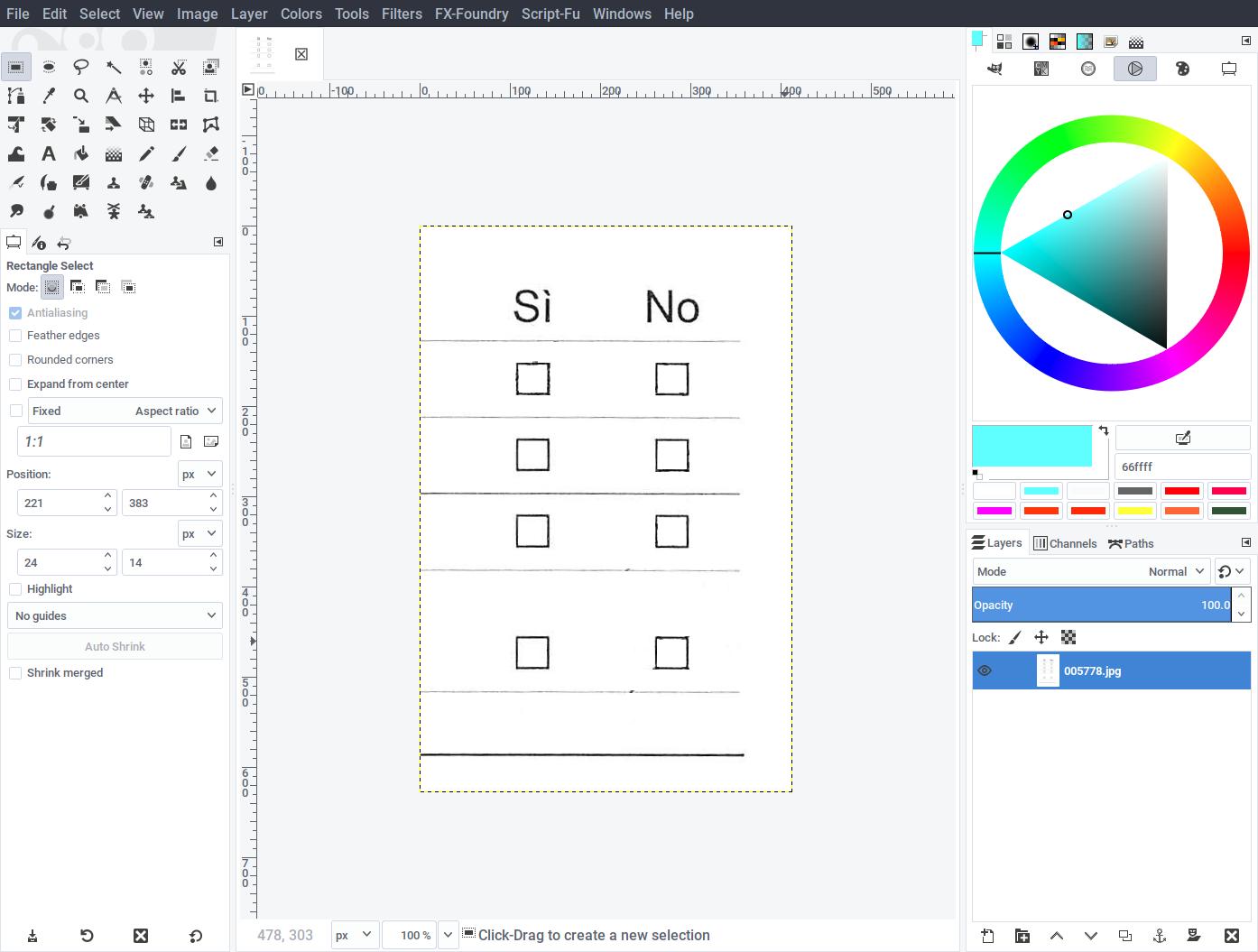
- Open the template (template.png) with Inkscape.
- Loosely draw a rectangle around each checkbox, trying to use the same size for all.
- Assign an unique ID to each drawn rectangle (right click -> Object properties … -> ID).
- Save the resulting file as checkboxes.svg.
Questionnaire processing
Scan all the pages in bulk at 300 dpi, grayscale. Process each page using the following pseudo-code:
for page in $pages do # find the template in the page ./bin/extractmpl template.png $page registered.png if [ $? == 0 ] then # template found, extract checkbox values ./bin/simpleomr checkboxes.svg registered.png > $page.txt fi done
The numerical values of the checkmarks in each page will be written into corresponding text files.
Calling extractmpl multiple times using different templates will allow to detect different questionnaires and do selective processing of the checkmarks just by checking its exit status.
Recognition accuracy

Templates used for recognition
Both the image matching and checkmark filling detection in RescueOMR are tuned to deal with worst case scenarios. The images on the left where used as a template for 10‘000 mixed documents. extractmpl was able to match and identify correctly both templates in 100% of the cases distributed over 4 document variations, ignoring about 500 unrelated pages. simpleomr identified correctly the checkmark values in 9300 images, with 200 images of uncertain results left for review. After a full manual review of the entire process, we spotted 2 cases which couldn’t be classified correctly and that we show below.
A sampler of these documents that you can use for experimentation is available in our tutorial. Some interesting results are outlined here:
Overcorrected mistakes
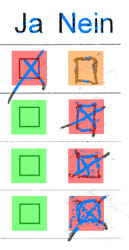
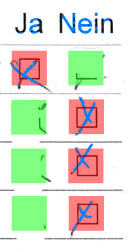
People get creative when correcting errors: why not erase the checkboxes instead of filling them? Despite the lack of features, the template still got recognized correctly.
In the left case, the squares were even re-drawn manually. It’s nice to note that straight-line rejection was good enough to mark the top-right cell as unknown: had the user been just a little bit more careful, the box would have been correctly marked as empty.
Poor quality printing
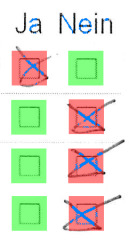
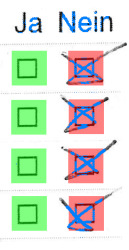
We were puzzled by the extremely poor quality of these prints, despite coming from the same printer as the others. We later found out that one of the workstations had the “toner saving” mode set by default.
In some cases a very thin and patterned line is generated, while in others all lines become thicker and distorted, actually not saving any toner at all.
Impossible to review
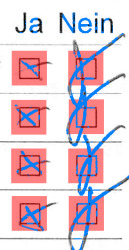
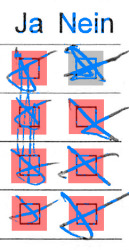
In a good portion of the images requiring user review, we couldn’t decide which result made sense with just the matched portion of the image.
This is a good reminder that a manual review process shouldn’t be skipped if the checkbox values are not coherent. Many pages included notes written on the side that could be used to unravel the mystery.
Misclassified
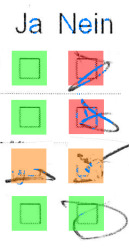
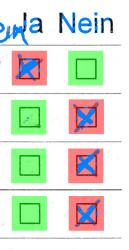
In the left image, the bottom-right checkbox wasn’t correctly identified as checked. The combination of low ink and the top line overlapping exactly the checkbox border fooled the straight-line rejection. A slightly bigger detection rectangle would have helped.
In the right case, the top-left checkbox was checked, but a comment was added just outside mentioning the opposite result. We could only notice this “error” after manual review.
Features and limitations
Traditional OMR software require questionnaires to be prepared with dedicated tools, or to add additional formatting/barcodes/marks for page registration. Processing a document that was not initially prepared for OMR is often hard or results in a very high error recognition rate even when using high-end printing and scanning equipment.
RescueOMR bypasses the image registration requirement by using image-matching directly. No special tools are required: a cleaned sample of the region to match is all it’s needed. By having no assumption on the underlying page structure, RescueOMR can easily find similar regions in different page layouts, often without multiple templates.
RescueOMR is generally not intended to substitute existing software when designing a new questionnaire from scratch. Software such as SDAPS or queXF offer integrated questionnaire design tools that can handle the entire processing workflow, from design to answer validation.
RescueOMR is also not a full OMR suite: it’s mainly designed to aid in digitalization of pre-existing paper questionnaires, often accompanied by custom scripting and validation.
RescueOMR settings and tolerances are tuned for 300 dpi gray-scale documents only. When scanning your questionnaires, be sure to set the scanning parameters to 300 dpi gray-scale, possibly without compression.
Requirements and installation
RescueOMR requires the following software packages:
- Python 3
- Python Imaging Library (PIL) (python3-pil)
- Python lxml (python3-lxml)
- NumPy (python3-numpy)
- SciPy (python3-scipy)
- scikit-image (python3-skimage)
Under Debian/Ubuntu, install the required dependencies with:
sudo apt-get install python3-pil python3-lxml python3-numpy sudo apt-get install python3-scipy python3-skimage
Technical documentation
extractmpl template design
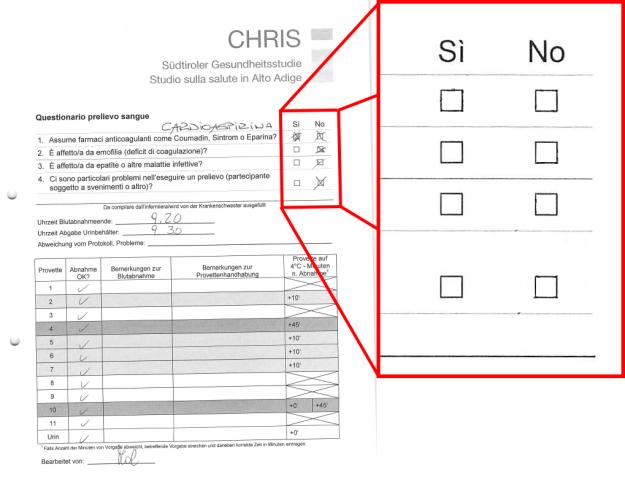
extractmpl works by locating edge features in the template that are also present inside the page. Details in the page which do not exist in the template are simply ignored (that is: extractmpl does a one-way search of the features contained in the template).
In Template preparation we outline two important details which are a consequence of these rules.
We instruct to crop the image to the area surrounding the checkboxes: we want the text nearby the checkbox to match exactly a single time in the page. Text surrounding the checkboxes is generally unique, while checkboxes by themselves are not. Cropping the template exactly around a single checkbox would match any checkbox in the page.
The template must be the smallest, visually unique area in the page (and more generally, unique in all the possible pages to be discerned).
Once an appropriate template region has been located, we want to ignore details which might change inside the page. As a consequence of the one-way match, we can simply remove any detail from the template that we want to ignore: if the page has been scribbled, simply remove any pen mark using an image editor. If there’s a variable code in the header of a page that we want to ignore, just clear the code from the template.
This behavior however has the unintended side-effect that a page can potentially contain unwanted additional features in any empty area of the template and still match. In such cases it’s then necessary to enlarge the template to include some other unique feature. In practice though, such scenario is very unlikely: careful template preparation becomes an issue only when similar pages are being analyzed, and it’s otherwise a trivial process.
extractmpl looks for the template in the entire page, allowing for a certain degree of deformation. Searching for the template is the slowest process by a large margin, but it can be sped-up by restricting the search area to a smaller region using the -r [region] flag. The specified region, specified in pixel coordinates from the top-left corner of the page, must always contain the template completely. As such, provide for a generous border around the expected position to account for all page shifts and distortions caused by the printer+scanner combination.
simpleomr template design
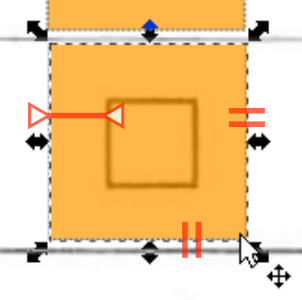
extractmpl will output the rectified area matching the template inside the page. That is, the output image will contain the checkboxes of each page at exactly the same coordinates as the template.
You can process the output directly yourself, or use simpleomr immediately in sequence. simpleomr contains ad-hoc logic to handle square checkboxes, with support for both simple marks, ticks, X-es, and filling.
The checkbox positions can be constructed conveniently using Inkscape. Create a new document, and import a single image: the template itself. Draw a single rectangle over each checkbox. Use the rectangle tool only: do not use any other tool, group or transform. Guides can be used for alignment.
When drawing the rectangle, you should go around the checkbox borders, leaving some internal padding (30-50% of the checkbox size is a good rule). simpleomr ignores perfectly orthogonal lines, effectively masking the checkbox borders automatically and accounting for any scribble going outside the designated checkbox area (which is very common).
The rectangles in the same template should preferably have all the same sizes for best results.
Assign an unique ID to each rectangle (right click -> Object properties … -> ID) that will become the key in the output table. Save the resulting file as an Inkscape SVG file or as a Plain SVG file.
simpleomr output
For each checkbox in the SVG file simpleomr will output a simple tab-separated table of the form:
| ID | value |
| ID | value |
| … | … |
Where each ID is assigned to a rectangle via Inkscape, and value can be:
| -1: | Unknown state |
|---|---|
| 0: | Empty |
| 1: | Checked |
| 2: | Filled |
simpleomr can also output an additional debugging image using the -d [file] flag. Such image shows how each pixel/location is considered by simpleomr:
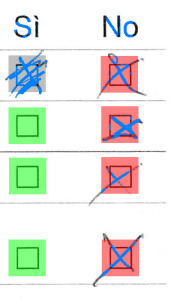
simpleomr debug image
| Blue areas: | pixel constituent |
|---|---|
| Yellow rect: | unknown |
| Green rect: | empty |
| Red rect: | checked |
| Gray rect: | filled |
| Other pixels: | ignored |
simpleomr has no notion of the checkbox semantics in the template. As such, it simply returns the fill status (empty/checked/filled) of each box. When pairs of checkboxes are used, as typical in a yes/no scenario, post-processing is often required for validating the true answer.
Authors and Copyright
RescueOMR can be found at https://www.thregr.org/wavexx/software/RescueOMR/
RescueOMR‘s GIT repository is publicly accessible at: